
What is Kafka?
Apache Kafka is a distributed and robust queue that can handle high volume data and enables you to pass messages from one end-point to another.
Kafka is
- Fast
- Scalable
- Durable
When used in the right way and for the right use case, Kafka has unique attributes that make it a highly attractive option for data integration.
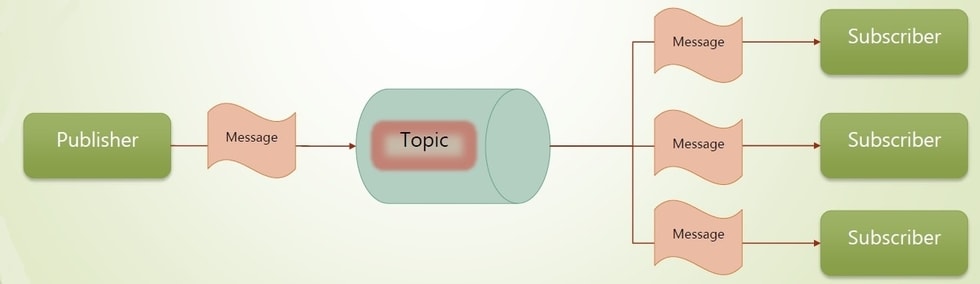
Publish subscribe messaging system
- Kafka maintains feeds of messages in categories called topics
- Producers are processes that publish messages to one or more topics
- Consumers are processes that subscribe to topics and process the feed of published messages
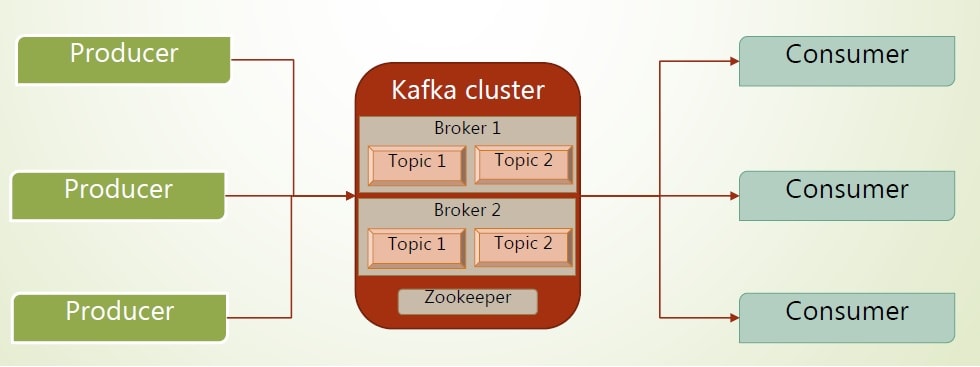
Kafka Cluster
- Since Kafka is distributed in nature, Kafka is run as a cluster.
- Kafka use Zookeper as distribution centralizer.
- A cluster is typically comprised multiple servers; each of which is called a broker.
- Communication between the clients and the servers takes place over TCP protocol.
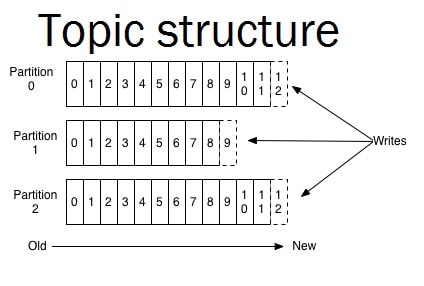
Topic
- Kafka uses Topic conception which comes to organize messages flow.
- To balance the load, a topic may be divided into multiple partitions and replicated across brokers.
- Partitions are ordered, immutable sequences of messages that’s continually appended i.e. a commit log.
- Messages in the partition have a sequential id number that uniquely identifies each message within the partition.
Partitions
- Partitions allow a topic’s log to scale beyond a size that will fit on a single server (a broker) and act as the unit of parallelism.
- The partitions of a topic are distributed over the brokers in the Kafka cluster where each broker handles data and requests for a share of the partitions.
- Each partition is replicated across a configurable number of brokers to insure fault tolerance.
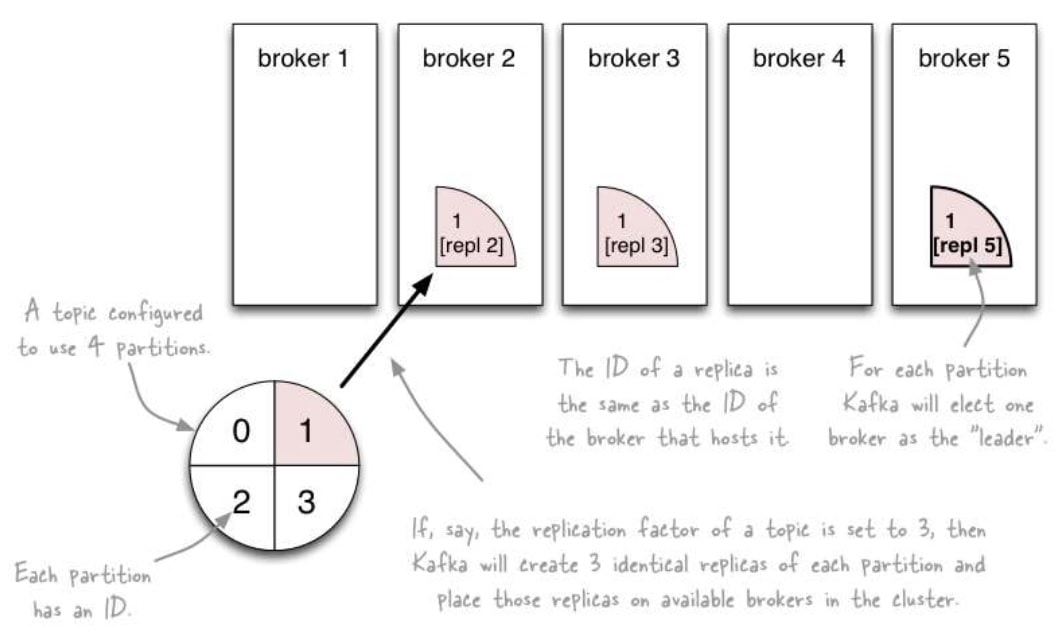
Fault Tolerance
- Each partition has one server which acts as the leader and zero or more servers which act as followers.
- The leader handles all read and write requests for the partition while the followers passively replicate the leader.
- If the leader fails, one of the followers will automatically become the new leader.
- Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Retention
- The Kafka cluster retains all published messages (whether or not they have been consumed) for a configurable period of time; after which it will be discarded to free up space.
- Metadata retained on a per-consumer basis is the position of the consumer in the log, called offset, which is controlled by consumer.
- Usually a consumer advances its offset linearly as it reads messages, but it can consume messages in any order.
- Kafka consumers can come and go without much impact on the cluster or on other consumers.
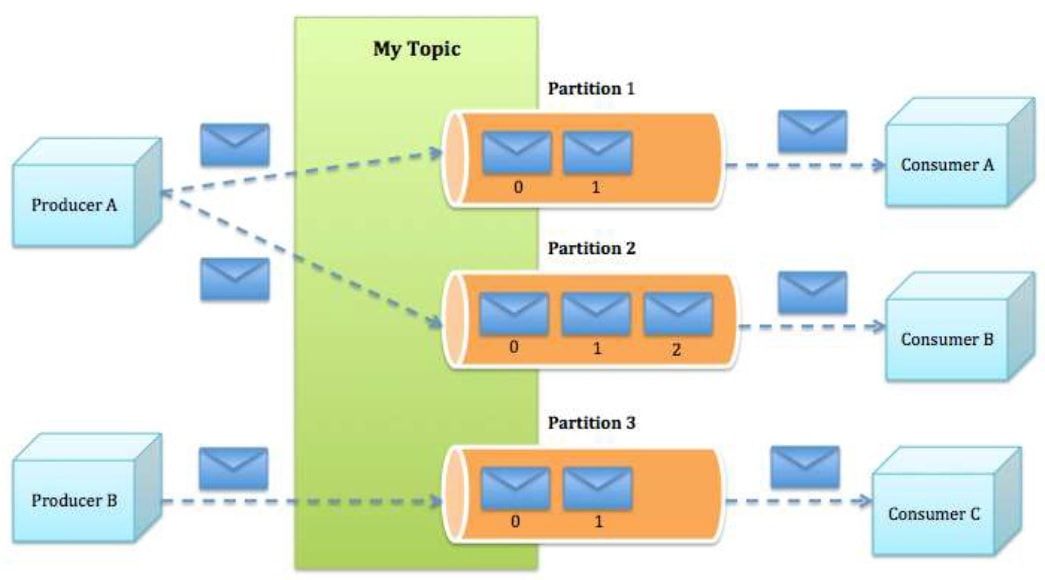
Producers
Producers publish data to the topics by assigning messages to a partition within the topic either in a round-robin fashion or according to some semantic partition function.
Consumers
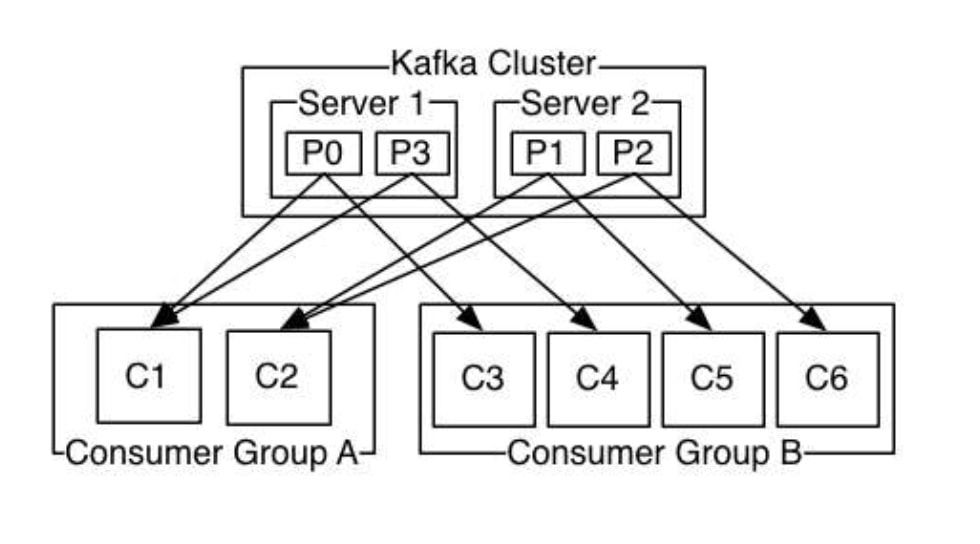
- Kafka offers a single consumer abstraction called consumer group that generalizes both queue and topic.
- Consumers label themselves with a consumer group name.
- Each message published to a topic is delivered to one consumer instance within each subscribing consumer group.
- If all the consumer instances have the same consumer group, then Kafka acts just like a traditional queue balancing load over the consumers.
- If all the consumer instances have different consumer groups, then Kafka acts like publish-subscribe and all messages are broadcast to all consumers.
Consumer Groups
- Topics have a small number of consumer groups, one for each logical subscriber.
- Each group is composed of many consumer instances to insure scalability and fault tolerance.
Ordering guarantees
- Kafka assigns partitions in a topic to consumers in a consumer group so, each partition is consumed by exactly one consumer in the group, but there cannot be more consumer instances in a consumer group than partitions.
- Kafka provides a total order over messages within a partition, not between different partitions in a topic.
Why Kafka?
Horizontally scalable
- Kafka is a distributed system that can be elastically and transparently expanded with no downtime.
High throughput
- High throughput is provided for both publishing and subscribing, due to disk structures that provide constant performance even with many terabytes of stored messages.
Reliable delivery
- Persists messages on disk, and provides cluster replication.
- Supports large number of subscribers and automatically balances consumers in case of failure.
Common Use Cases
- Stream processing, event sourcing, traditional message broker replacement.
- Website activity tracking – original use case for Kafka.
- Metrics collection and monitoring – centralized feeds of operational data.
- Log aggregation.











[…] Image Source: http://www.codeflex.co […]
[…] Well explained in this article : http://codeflex.co/what-is-apache-kafka/ […]