
Redis Cluster was released on April 1st, 2015. Since then Redis Cluster is the preferred way to get automatic sharding and high availability.
In this article you’ll see step by step tutorials about how to install and configure Redis Cluster on Linux.
Installation
Run the following on your Linux environment:
wget http://download.redis.io/releases/redis-3.2.1.tar.gz tar xzf redis-3.2.1.tar.gz cd redis-3.2.1 make
The binaries will become available in src directory.
In order to install Redis binaries into /usr/local/bin just use this command:
% make install
You can use “make PREFIX=/some/other/directory install” if you wish to use a different destination.
make install PREFIX=/export/home/rightv/redis
Redis cluster topology
Minimal cluster that works as expected requires to contain at least three master nodes.
Redis recommendation is to have at least one slave for each master.
- Minimum 3 machines
- Minimum 3 Redis master nodes on separate machines (sharding)
- Minimum 3 Redis slaves, 1 slave per master (to allow minimal fail-over mechanism).
In our example we will use 3 master and 3 slave nodes accordingly.
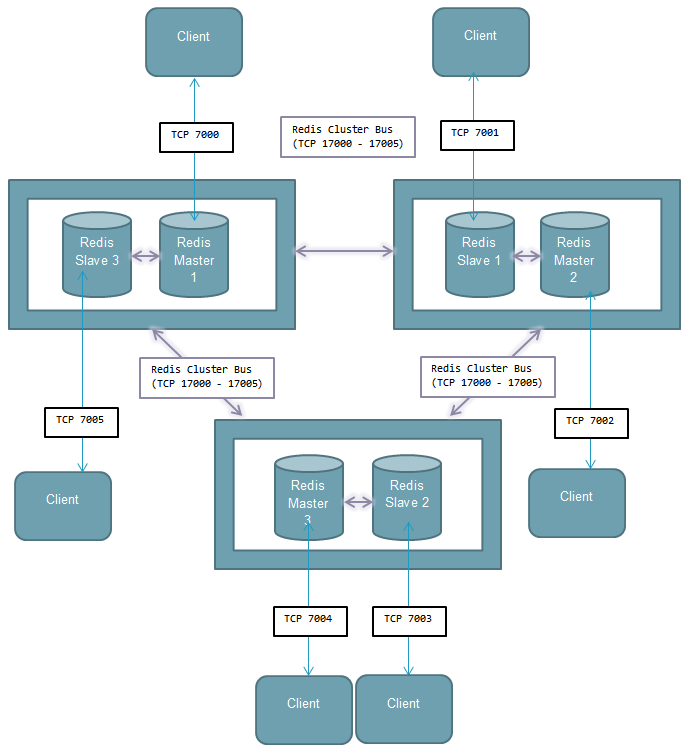
In case if one of masters goes down, his slave will become a master. It is possible to add/remove nodes on the fly.
Redis Configuration File (redis.conf)
Each Redis node has its own configuration file (redis.conf). In order to run Redis in cluster mode we must set cluster-enabled yes for each node.
Here is our redis.conf file. Notice that port and bind values will be different for each node. I set port 7000 for each master and port 7001 for each slave in this example.
port 7000 bind 172.31.160.110 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 cluster-slave-validity-factor 1 logfile redis.log loglevel notice slowlog-log-slower-than 10000 slowlog-max-len 64 latency-monitor-threshold 100 maxmemory 64mb maxmemory-policy volatile-ttl slave-read-only yes save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbchecksum yes dbfilename dump.rdb appendonly yes
Once we have configured redis.conf for each redis instance (node) we can launch them:
./redis-server redis.conf
IMPORTANT: Start each redis instance only from directory where redis.conf is located!
For example: if our master located here: /home/codeflex/redis/7000 then we start the redis instance from that location.
Once you’ve performed this you will notice that in each redis directory will be created dump.rdb and nodes.conf files.
dump.rdb contains database recovery information and nodes.conf stores redis nodes configuration. You should not edit these files.
Redis Slots Allocation
There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Every node in a Redis Cluster is responsible for a subset of the hash slots, so for example you may have a cluster with 3 nodes, where:
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
This allows to add and remove nodes in the cluster without downtime.
For example if I want to add a new node D, I need to move some hash slot from nodes A, B, C to D. Similarly if I want to remove node A from the cluster I can just move the hash slots served by A to B and C. When the node A will be empty I can remove it from the cluster completely.
In order to allocate slots we need to run following commands in bash:
for i in {0..5400}; do ./redis-cli -h 10.20.21.44 -p 7000 CLUSTER ADDSLOTS $i; done
for i in {5401..10800}; do ./redis-cli -h 10.20.21.113 -p 7000 CLUSTER ADDSLOTS $i; done
for i in {10801..16383}; do ./redis-cli -h 10.20.21.59 -p 7000 CLUSTER ADDSLOTS $i; done
Then if you’ll run this command you can verify that slots been allocated successfully:
redis-cli -h 10.20.21.44 -p 7000 CLUSTER NODES
Output: e898985408ad6a49d714b82c1e157276d4681ae9 10.20.21.44:7000 myself,master - 0 0 1 connected 0-5400
Cluster formation
Now when all the 16384 hash slots are allocated and all 6 instances are running we need to tell them to meet each other. Thus every node will “know” everyone.
redis-cli -h 10.20.21.44 -p 7000 CLUSTER MEET 10.20.21.44 7001 redis-cli -h 10.20.21.44 -p 7000 CLUSTER MEET 10.20.21.113 7000 redis-cli -h 10.20.21.44 -p 7000 CLUSTER MEET 10.20.21.113 7001 redis-cli -h 10.20.21.44 -p 7000 CLUSTER MEET 10.20.21.59 7000 redis-cli -h 10.20.21.44 -p 7000 CLUSTER MEET 10.20.21.59 7001
Configure Replication
Now, when all nodes are connected into cluster we need set replications. In other words we need to define what nodes are masters and what nodes are their slaves:
./redis-cli -h 10.20.21.113 -p 7001 CLUSTER REPLICATE e898985408ad6a49d714b82c1e157276d4681ae9 ./redis-cli -h 10.20.21.59 -p 7001 CLUSTER REPLICATE 93e74c3c5cc0328755ba24cbc9b166439dac4e93 ./redis-cli -h 10.20.21.44 -p 7001 CLUSTER REPLICATE bced1d26ffc236fdaeffe9864f155c7a55a0a3b0
If you will run redis-cli -h 10.20.21.44 -p 7000 CLUSTER NODES you will see something like this:
974502302670a8aa78280c9d414ba11b9a8e1133 10.20.21.113:7001 slave e898985408ad6a49d714b82c1e157276d4681ae9 0 1461157218265 2 connected 837408b39322813f09ff285c6e8545c9533386f6 10.20.21.59:7001 slave 93e74c3c5cc0328755ba24cbc9b166439dac4e93 0 1461157217763 5 connected bced1d26ffc236fdaeffe9864f155c7a55a0a3b0 10.20.21.59:7000 master - 0 1461157216260 4 connected 10923-16383 e898985408ad6a49d714b82c1e157276d4681ae9 10.20.21.44:7000 myself,master - 0 0 1 connected 0-5461 93e74c3c5cc0328755ba24cbc9b166439dac4e93 10.20.21.113:7000 master - 0 1461157217765 5 connected 5462-10922 fe417e558b7f9a7c99e56f4f825980940c9ed589 10.20.21.44:7001 slave bced1d26ffc236fdaeffe9864f155c7a55a0a3b0 0 1461157217763 4 connected
Verify Redis Cluster is working properly
In order to check if our Redis cluster working properly lets insert some key-value:
./redis-cli -h 172.31.150.113 -p 7000 -c 172.31.150.113:7000 > set somekey somevalue -> Redirected to slot [11058] located at 10.20.21.59:7000 OK
When you insert some data into Redis cluster special hash function calculates the appropriated slot for it.
You can see from output that despite we referred to node on 172.31.150.113 Redis automatically put the data on corresponding node (10.20.21.59). This means that our Redis cluster is working properly.
Fail-over Procedure
Our cluster configuration consists of 3 servers with one master and one slave of different index on each server.
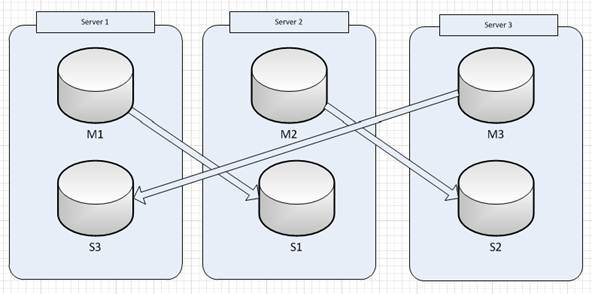
When one of the servers goes down then Redis Cluster will perform automatic failover process that will force the slave to become a master instead of failed master.
For instance let’s say that Server1 goes down, then after fail-over process performed (usually couple of seconds) and Server 1 was restarted the Redis Cluster structure becomes like this:
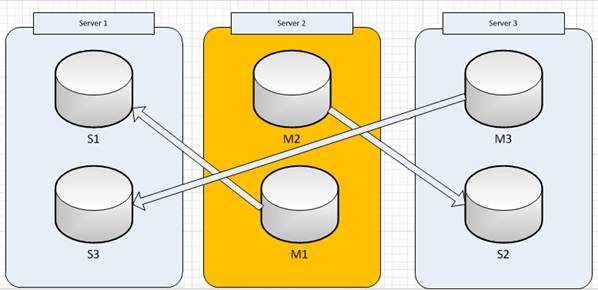
The Cluster is in working mode, but in this case we have potentially dangerous situation when on the same server there are two masters (Server2)
This is the case when administrator should perform an after failover procedure which will rearrange the Cluster structure in such way that on each server will be one single master and a slave of some other master.
The procedure is following:
- On Server2 administrator need to stop the M1 redis instance:
service redis7001 stop - After a couple of seconds ensure that cluster failover mechanism took place – S1 became a master (M1) with arranged slots. (note that cluster will be in failure state during this process)
- Start redis instance on Server2:
service redis7001 start - Ensure that second redis instance on Server2 became a slave of the first instance on Server1 and that the cluster structure returned to its initial state
Redis Java Client
Redisson is my preferred Java Redis client since it supports Cluster server mode with automatic server discovery and Spring cache integration. Also, I received really fast and reliable support when I found some minor bugs.
Redisson is based on high-performance async and lock-free Java Redis client and Netty 4 framework.
Redis 2.8+ and JDK 1.6+ compatible and licensed under the Apache License 2.0.
Some other Redisson features:
- Spring cache integration
- AWS ElastiCache servers mode:
- automatic new master server discovery
- automatic new slave servers discovery
- Cluster servers mode:
- automatic master and slave servers discovery
- automatic new master server discovery
- automatic new slave servers discovery
- automatic slave servers offline/online discovery
- automatic slots change discovery
- Master with Slave servers mode: read data using slave servers, write data using master server
- Single server mode: read and write data using single server
- Supports auto-reconnect
- Supports failed to send command auto-retry
- Supports many popular codecs (Jackson JSON, CBOR, MsgPack, Kryo, FST, LZ4, Snappy and JDK Serialization)
If you have any questions, please write us in the comments section bellow.











Hi,
Wonderful explanation. Glad I found this.
I have questions regarding the startup/shutdown of redis servers as in the above example.
1. Will the clustering be automatically setup when you restart the unix servers in the event of a reboot? (assuming init file has the redis start commands)
[I am assuming yes, based on the information in nodes.conf file]
2. Is there a sequence of which redis instance to stop before the reboot or does it even matter?
Thanks
Hi,
How can I specify that port 7001 are slaves?
Can you please provide conf files for 7001 also?
When you use the command :
redis-cli -h localhost -p 7001 CLUSTER REPLICATE (NODE ID)
you also configure the “localhost” as the slave
When i replicate using below commands:
./redis-cli -h localhost -p 6378 CLUSTER REPLICATE abc563654fafgsajnfn454
Could not connect to Redis at localhost:6378: Connection refused
Could not connect to Redis at localhost:6378: Connection refused
Can someone pls suggest.
Hi,
Master port:6379
slave port: 6378
./redis-cli -h 172.5.6.1 -p 6379 CLUSTER NODES
ab9745b7784b739772a37b621abd3b74015c3420 :6379 myself,master – 0 0 0 connected 0-5400
./redis-cli -h 172.5.6.2 -p 6379 CLUSTER NODES
fd005ca7a8432d54ab7d28e8f52324bf8fcadda6 :6379 myself,master – 0 0 0 connected 5401-10800
./redis-cli -h 172.5.6.3 -p 6379 CLUSTER NODES
deba5c9f902fa3dc90dfbab2ce804a441d36ea1a :6379 myself,master – 0 0 0 connected 10801-16383
./redis-cli -h localhost -p 6378 CLUSTER REPLICATE deba5c9f902fa3dc90dfbab2ce804a441d36ea1a
./redis-cli -h localhost -p 6378 CLUSTER REPLICATE ab9745b7784b739772a37b621abd3b74015c3420
./redis-cli -h localhost -p 6378 CLUSTER REPLICATE fd005ca7a8432d54ab7d28e8f52324bf8fcadda6
./redis-cli -h localhost -p 6378 CLUSTER REPLICATE deba5c9f902fa3dc90dfbab2ce804a441d36ea1a
Could not connect to Redis at localhost:6378: Connection refused
Could not connect to Redis at localhost:6378: Connection refused
Hello,
Thank for the great post. I want to know which IP application should point to Redis cluster. (My application doesn’t support Redis cluster)
You may point to any master node.
When I initially commented I seem to have clicked the -Notify me when new comments are added- checkbox
and from now on every time a comment is added I
get 4 emails with the exact same comment. Perhaps there is a way you are able to remove me from
that service? Cheers!
H, great tutorial, just a remark : I believe your config files are missing the ‘daemonize yes’
[…] Io non sono sicuro di quello che stai chiedendo. Redis Cluster è ancora in versione beta. Redis di Replica è stato lì per anni, e ha avuto un enorme aggiornamento in 2.8.4 con vari miglioramenti. Per 1 master e 1 slave hai solo bisogno di replica. Basta fare una “slave” slave e sei a posto. Il miglior tutorial su Redis di installazione di un cluster: codeflex.co/configurazione-redis-cluster-su-linux […]
Hi, Great tutorial, I have found one issue in the redis cluster, would you please help me. I had set up redis cluster in three different servers and each server contain one master and slave also set up same password for all servers. While storing a value through redis-cli, it redirects to another server in the cluster and failing as authentication error.
ex: x.x.x.110:7001 redis-cli> auth password
x.x.x.110:7001 redis-cli> set x 9
x.x.x.110:7001 redis-cli> redirected to x.x.x.111:7001 authentication error
x.x.x.111:7001 redis-cli>
Though I have authenticated initially, while redirecting to another server in the cluster, getting authentication error.